Amazon Web Services (AWS) offers a fully managed Kubernetes solution called Amazon Elastic Kubernetes Service (Amazon EKS). It facilitates both on-premises and cloud management of your containerized apps.
EKS monitoring entails keeping an eye on and recording your EKS clusters’ health and performance. In order to ensure high availability and optimal performance of your Kubernetes workloads, detect issues before they become serious ones, and figure out how to enhance the performance and utilisation of your EKS deployments, effective monitoring is essential.
Observability in AWS EKS
Observability refers to the ability to understand a system’s state by observing its external outputs. In the context of Amazon EKS, observability entails understanding the state of your EKS clusters by inspecting logs, metrics, and traces. By ensuring that EKS clusters generate the correct signals, you can identify problems faster, troubleshoot more efficiently, and optimise your clusters for improved performance.
Understanding the dependencies and interactions between workloads in your Amazon EKS clusters is also part of observability. This is critical in a microservices architecture, where multiple services communicate with one another. Understanding these interactions allows you to identify bottlenecks and optimise workloads for increased performance and reliability.
To achieve observability in EKS, you must address several layers, including the EKS control plane, EKS worker nodes, and the workloads and applications running in your Kubernetes clusters.
AWS EKS Monitoring Metrics
Monitoring the health of your EKS clusters and applications is crucial for maintaining their performance and availability. This involves monitoring key health indicators at all levels—Kubernetes control plane, node, and application.
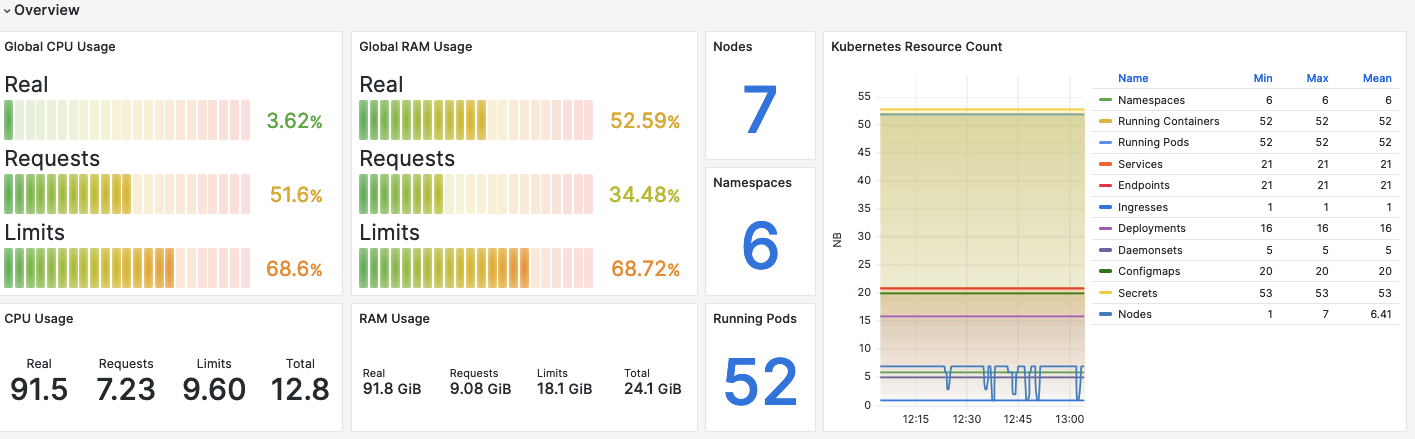
Global View
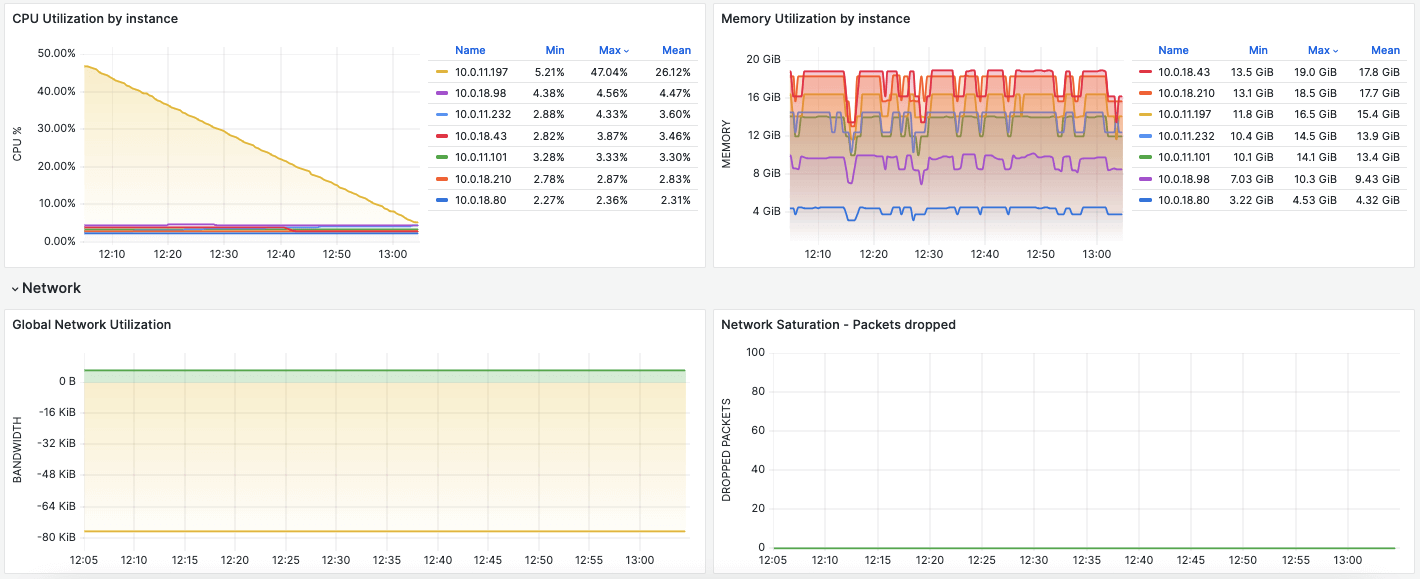
Monitoring at the cluster level provides a high-level view of Kubernetes’ health and overall performance. Key metrics to monitor include:
Cluster Status: Regularly check the status of the cluster to ensure that it is operational. Monitor the control plane’s health, including the API server, scheduler, and etc. (a key-value store for cluster data).
Resource Usage: Track the usage of CPU, memory, and storage across the cluster. This helps in understanding resource allocation and pinpointing bottlenecks.
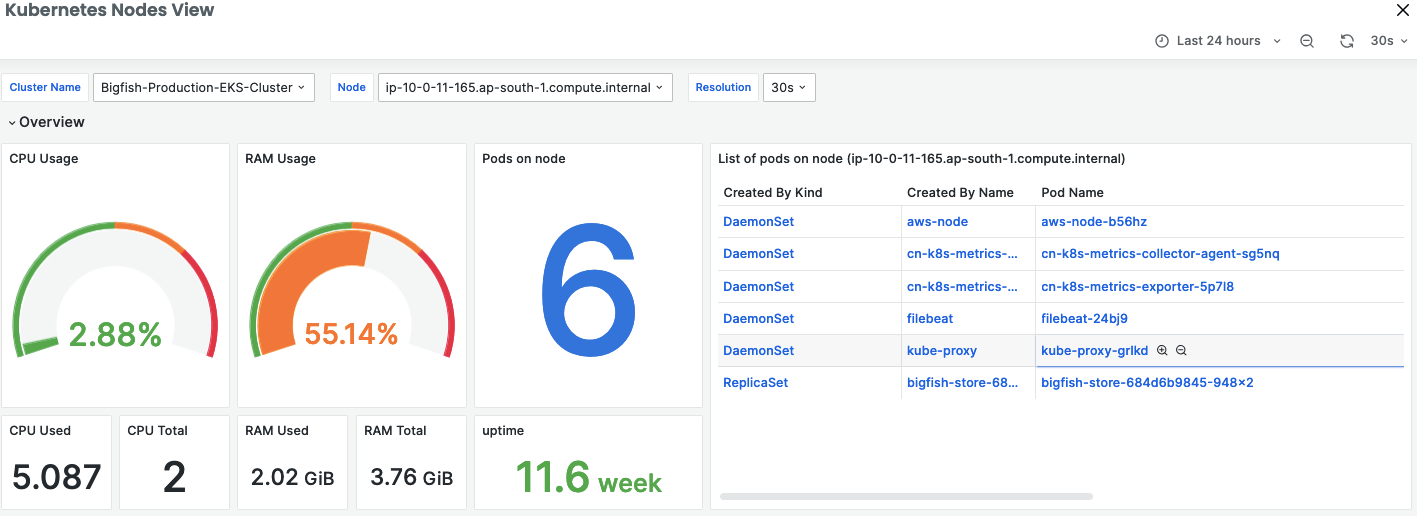
Node Metrics View
Node-level monitoring focuses on the performance and status of the worker machines. Important metrics include:
Node Performance: Monitor metrics such as CPU, memory, disk, and network usage. High usage might indicate that your node is a bottleneck.
Node Status: Check whether nodes are in Ready state or if they have issues that prevent them from serving workloads.
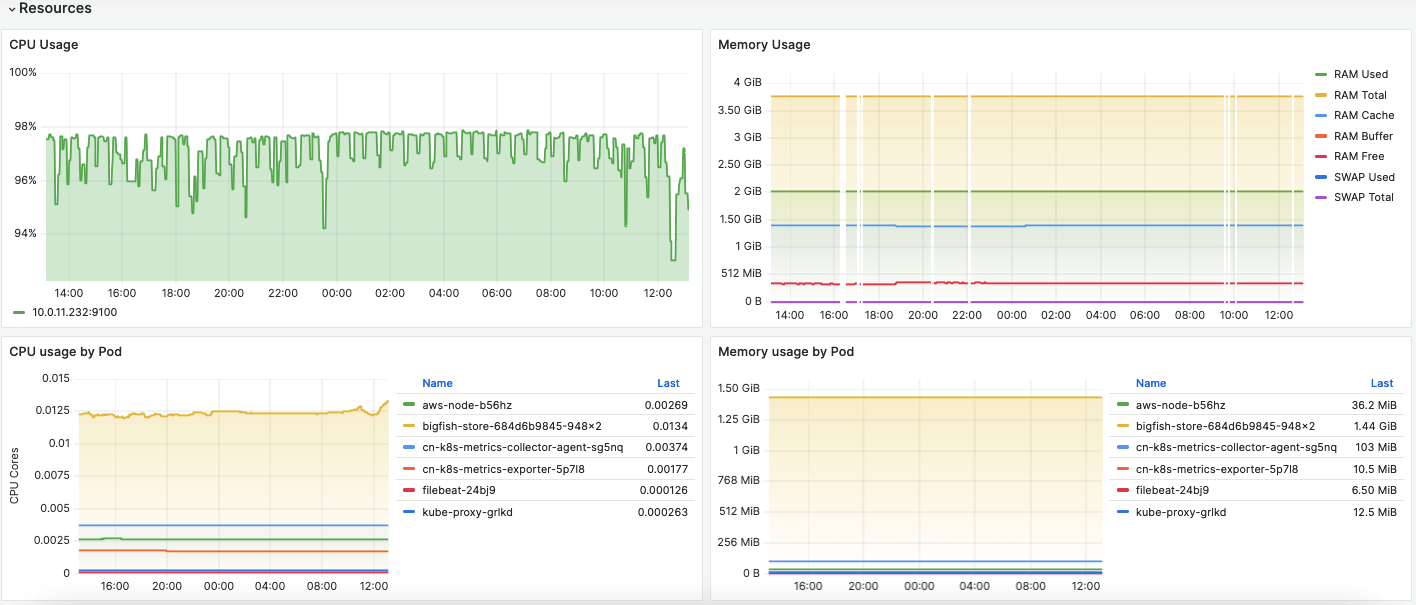
Pod Metrics View
Pod monitoring is crucial for understanding how applications and services are performing. Essential aspects to monitor include:
Pod Status: Keep track of pod statuses, such as Running, Pending, Failed, or Crashed. Monitoring these statuses helps quickly identify issues at the application level.
Resource Consumption: Monitor the resources each pod is consuming. High resource consumption can affect pod performance and availability.